Webサーバー・各言語の処理能力が向上している近年では、正規表現のコストパフォーマンスを意識することはあまりないように思います。
ですが、エンジニア職としてコストパフォーマンスを考えることは重要だと思いますし、何かの役に立つかもしれないので、コストパフォーマンスについて今回は書いてみようと思います。
貪欲な正規表現と非貪欲な正規表現
まずは同じ例文を貪欲な正規表現と非貪欲な正規表現で分割してみます。
const text = 'He said that that that that that girl used was wrong.';
// 以下順に貪欲な正規表現と非貪欲な正規表現
const greedyResult = /(.*) that (.*)/.exec(text);
const nonGreedyResult = /(.*?) that (.*)/.exec(text);
/*
* 実行結果
* greedyResult[1] : 'He said that that that that'
* greedyResult[2] : 'girl used was wrong.'
* nonGreedyResult[1] : 'He said'
* nonGreedyResult[2] : 'that that that that girl used was wrong.'
*/※「.*」: 任意の文字列を表す正規表現(貪欲)
※「.*?」: 任意の文字列を表す正規表現(非貪欲)
このように貪欲なマッチでは、先頭の「.*」ができるだけ最大の長さになるようマッチします。
非貪欲なマッチではその逆で、先頭の「.*?」が最小の長さになるようマッチします。
今回の例では実行結果が違いますが、貪欲・非貪欲どちらの正規表現でも同じ実行結果になることがあります。
この場合、貪欲・非貪欲な正規表現がコストパフォーマンスに影響します。
バックトラッキング
正規表現ライブラリには、バックトラッキングというアルゴリズムが利用されています。
正確には利用していないライブラリもあるのですが、説明が長くなるのでその他のアルゴリズムに関しては説明しません。
言葉だと伝わりにくいので、まずは郵便番号を分割する、正規表現アルゴリズムの各ステップを見ていきたいと思います。
以下の画像は、ステップ数を視覚的に表示してくれるサイトOnline regex tester and debuggerを利用しました。残念ながらPHPのみの対応でしたが、基本的には各言語でも同じような結果になります。
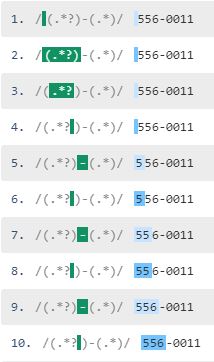
貪欲な正規表現のステップ

{kind=link}

合計19ステップになりました。先頭の「.*」が’556-0011′ => ‘556’に範囲を縮小していくのを確認してもらえると思います。これをバックトラッキングといいます。
先頭の「.*」(貪欲)とバックトラックの組み合わせが、無駄なステップが実行される原因になります。
非貪欲な正規表現のステップ
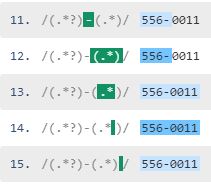
合計15ステップになりました。先頭の「.*?」が’5’=>’556’に範囲を拡大していくのを確認してもらえると思います。
今回は簡単な例なのであまり差がありませんが、長い文章を正規表現で扱うと顕著な差ができちゃうので注意が必要だと感じました。
以上。